Detailed Workflow¶
FlowStrider implements a custom workflow inspired by practical experience. The following sections provide a detailed description of each step in the workflow. A simple example is used to illustrate the process, showing the processing by FlowStrider in figure 1 and the example data-flow diagram in figure 2.

Fig. 1: Diagram of flowstrider workflow¶
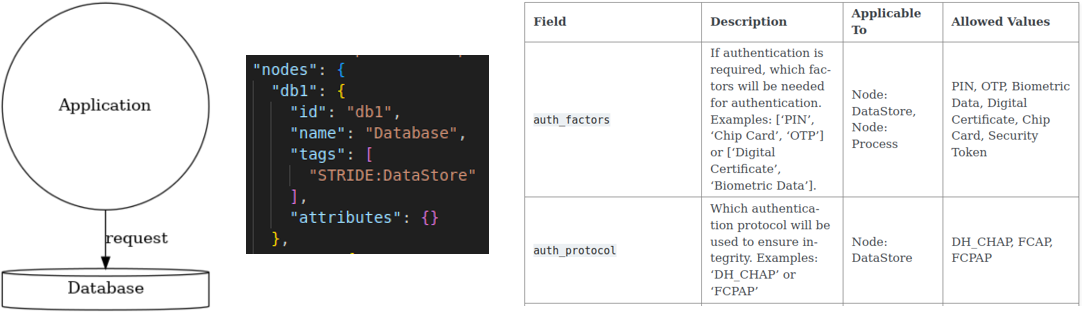
Fig. 2: Overview of data-flow diagram (dfd) and possible metadata¶
Tip
For the actual commands needed to operate FlowStrider see FlowStrider or use
flowstrider --help
Data-Flow Modeling¶
The first step of the process involves creating an abstract model of the software system under test, resulting in a data-flow diagram (dfd). Since the security-relevant metadata of the diagram elements play a crucial role in the threat modeling, we introduce an additional feature that enables the efficient inclusion of metadata. This enhancement refines the diagram and consequently improves the quality of the modeling results. The components of this process step are explained in more detail below.
Data-Flow Diagram¶
FlowStrider accepts as input a file that describes the software system using FlowStrider’s json-based data-flow diagram (DFD) format, making it independent of the system’s programming language. An example of a simple data-flow diagram is shown in figure 2. A data-flow diagram consists of five fundamental elements: processes, data stores, external entities, data flows, and trust boundaries, that can each be represented through simple geometrical shapes. For more information on how to create a data-flow diagram for a system, see Data-Flow Diagram.
Adding Metadata¶
Each of the elements in the dfd can be annotated with metadata attributes such as encryption methods, hash functions, and other security-related metadata that capture relevant security characteristics. This detailed representation aims to describe the system as accurately as possible to ensure the quality of the modeling results. A complete list of supported metadata is available in the section Data-Flow Diagram. The attribute set can also be easily extended to support additional domains and methodologies.
Manually specifying metadata attributes for each element in a data-flow diagram is a time-consuming task, and it is often unclear which attributes are relevant for modeling. Based on our experience, only few metadata is typically filled in initially which can negatively impact the quality of the modeling results and lead to a high number of false positives. This issue arises because FlowStrider performs the threat modeling pessimistically: if an attribute required to check for a threat is missing, we assume that the threat occurs.
To address this, FlowStrider includes a feature that analyzes the selected threat catalogs to identify which metadata is missing for each element in the data-flow diagram. It then generates an Excel file in which users can conveniently fill in the missing required values through text input or selecting sensible options. This file is subsequently read back into FlowStrider, and the data is automatically merged into the original data-flow diagram file. In our example from figure 2, one could for example add the value CHAP to the metadata Authentication Protocol (or auth_protocol internally) of the Database node, to define that the Database uses CHAP for authentication.
This process allows users to iteratively and efficiently add important metadata, improving both usability and the quality of the modeling results. The Excel format enables easy communication between disciplines in large organizations.
Customizability and Extensibility¶
An important characteristic of FlowStrider is its adaptability and extensibility, which enables its use across a wide range of software project domains and threat modeling methodologies. Particular emphasis is placed on the underlying data model of the data-flow diagram which is designed to be easily extendable. To facilitate this, each diagram element contains an open attribute Python dictionary that can be populated with relevant metadata. A detailed overview of the metadata currently supported by FlowStrider is available under the section Data-Flow Diagram.
In addition to the flexible data model, FlowStrider makes it easy to incorporate new rule sets such as legal regulations, industry standards, or project-specific policies. To support this extensibility, threat definitions are decoupled from the program logic. Instructions for adding custom threats are also provided in the documentation.
Knowledge and Processing¶
This process step forms the core of FlowStrider and is responsible for identifying threats using the data-flow diagram and the provided rule set. The two main components of this process are explained in detail below.
Rule set¶
An essential component of the threat modeling is the rule set which is evaluated against the data-flow diagram. Each rule set contains a set of rules with descriptions, possible mitigations, and the conditions under which it applies and generates a threat.
Rule sets to be used for the modeling can be specified via tags in the data-flow diagram file. Currently, the tool includes two predefined rule sets, but custom ones can be added as seen in the section Rule Sets.
Threat Elicitation¶
This is a core component of the tool, where the specified rule set is evaluated against the given data-flow diagram. STRIDE-per-Element is used as the core method, evaluating threat conditions for each element in the diagram. The threat modeling follows a pessimistic approach: if required information — such as additional attributes necessary for evaluating a threat — is missing, the threat is considered to occur.
The results of the modeling can be output directly on the command line or as a PDF report.
If we let FlowStrider elicit the example from figure 2 under the bsi_rules without any metadata attributes set, we get various threats such as Hashing of Passwords at the location of the Database, as we haven’t defined a hash algorithm for the Database and have not defined that the Database is not storing passwords/credentials. In this case the rule set assumed the worst and generates the corresponding threat. If we modify the metadata of the Database, so that Stores credentials is set to False, the threat will no longer occur at this position.
Additionally, this step supports an argument for integration into a CI/CD pipeline which is important for seamless and continuous integration into the software development process and lowers the barrier to adoption. The CI/CD capability also provides an incentive to keep the data-flow diagram in version control next to the code, reducing the chance of divergence over time. In this context, the modeling results and corresponding threat management decisions are used to assess whether the configured security policy is being met. See CI/CD Integration on how to integrate FlowStrider into CI/CD.
Documentation and Management¶
Documentation¶
This step focuses on evaluating the threat modeling results which are provided as a PDF report or via the command line. Based on this information, threat management can be performed by determining how each identified threat should be handled.
Threat Report¶
The threat report compiles the modeling results in a structured and readable PDF document, as partially shown in figure 1. It includes a visualization of the data-flow diagram, an overview of the identified threats, and a detailed breakdown of each detected threat sorted by rules with:
Threat source
Severity
Description / Long Description (References)
Mitigation options
Requirements
Locations (affected elements)
The Threat source indicates the name of the rule from which the following threats were generated. The threat sources are numbered starting from #1.
The Severity
is supposed to indicate the importance of the threats under this rule and depends on the
rules themselves and potential sensitive locations where the threats occured. See
Data-Flow Diagram for more details on how to manipulate the severity. The severity also
defines the order in which the threats are sorted with higher severity being at the top
of the elicitation results and the severity decending downwards. Rules with the same
severity are ordered alphabetically. Normally all threats generated by one rule are
listed under this specific rule with their locations so as not to repeat the description
unnecessarily. However, if there are threats from one rule with differing severity,
their threat source will appear multiple times so as to maintain the descending order of
the severity among the threats. If this happens, the name of the threat source is
followed with a number in parantheses for better readability (e.g. #5 Threat source:
Hashing of Passwords (1)). This way, all threats always have the exact same severity as
stated at the beginning of the rule, they are listed under.
The Description contains more information on the background of the rule for better understanding on why threats were elicited.
For most rules, Mitigation Options are stated below, giving ideas on how to improve the system to avoid the threats.
For more concrete information on why this rule generated threat(s) and how to avoid them specifically, see the Requirements of the rule. If all stated requirements are met for a location, the rule should not be elicited anymore there.
The Locations list all locations by name where the rule generated a threat, the current status of relevant metadata at this location (if applicable) and the current management state of this threat.
Output Formatting¶
Because the threat reports can get quite long for bigger projects, there are arguments to customize the way flowstrider displays the elicitation results on the console and on the PDF. The following arguments can be appended to a regular elicitation command. They only influence the way the threats are being displayed and can be left out for the default display style.
[--filter *filter_option*] (default=none): filters the threats to only display the
ones that fullfill all of the given options from different filters. Multiple filters
can be set
by using the --filter argument multiple times. Applicable filter keywords are
severity, rule_set, location and management_state. Following the
keyword, an operator and a value for the keyword is set. Allowed operators are
=, !=, <, >, <=, >= for severity and =, != for the other keywords. The value
has to be a float for severity, one or more rule set tags for rule_set, one or
more ids for a location in the dfd for location and one or more management_states
for management_state. Multiple values are seperated by comma and only one of the
values has to be met by a threat to pass an individual filter.
Examplary, --filter "severity>1.0" will only show threats with severity over 1.0,
--filter "location=node1_id,edge1_id" shows only the threats found at node1 or
edge1,
--filter "rule_set!=bsi_rules" only shows threats that did not come from the
bsi_rules rule set and
--filter "management_state=Delegate" --filter "severity<=2.0" will only show threats
that both have the management_state Delegate asigned in a given management file and have
at most 2.0 severity.
[--sort *sort_options*] (default="r-severity,alphabetical_source"): sorts the
threats by the given criteria. Applicable criteria are severity,
alphabetical_source, alphabetical_location. Each criteria can be prepended with
r- to allow for inverted sorting. Multiple criteria can be combined with comma for
secondary sorting.
Examplary, --sort "severity" will sort the threats with ascending severity and
--sort "r-alphabetical_source,r-severity" will sort primarily by reverse
alphabetical threat source name and secondarily by descending severity.
[--group *grouping_options*] (default=none): groups the threats by the given option.
By default, the threats are already grouped by each individual combination of threat and
severity. This means all threats from source test_source with severity 2.0 would go
together and all threats from test_source with severity 1.0 would go together. With
this argument, an additional grouping on top of that basic grouping can be applied. The
groups will be marked as such in the output and include all the threats with the same
characteristics for the grouped parameter. Applicable grouping options are
source (grouping by threat source), rule_set, location and
management_state.
[--quiet]: limits the output on the console and the PDF to save space and give a
more compact overview. All threats are still being shown, but things like descriptions
and management state are hidden.
Tip
It is recommended to encase the argument options in quotation marks, because commas, equal signs and other special characters won’t be interpreted as part of the argument otherwise.
Threat Management¶
In addition to identifying threats, managing and documenting them are crucial parts of the overall process. This includes assigning a management status to each threat—such as accept, delegated, mitigated, or undecided. For this purpose, a separate json file is used, which contains all identified threats along with their respective statuses and optional comment fields for documentation. This file can be updated during subsequent executions of the threat elicitation step and the decisions are incorporated into the generated report.
If we maintain a management file for our example from figure 2 and pass it to FlowStrider in each elicitation process, we are able to ignore a threat such as Hashing of Passwords at the Database node by setting the state of the corresponding threat to a state like Mitigated in the management file manually. By filling out the explanation field, we can also inform others of how we came to the mangement decision for this threat.
At the start of the threat management files, the version it was saved in is stated, so
flowstrider can
compare with the current internal version for the threat management files. If the file
is outdated, a warning will be thrown when using it with the tool. The current threat
management version can be checked with flowstrider info.
CI/CD Integration¶
FlowStrider is fully scriptable, enabling straightforward integration into CI/CD
pipelines. Using the fail-on-threat argument, users can define the threat
management status at which FlowStrider should raise an error and cause the pipeline to
fail. This behavior is based on the threat modeling results and the corresponding threat
management decisions. For example, the pipeline can be configured to block a release if
any threat remains unresolved or unaddressed.